TLDR: We encountered a slow, gradual rise in loss after progress towards convergence. We traced the issue to a misalignment in forward pass and backward pass calculations. This happened when using an open-source implementation of checkpointing provided by OpenAI in their guided-diffusion repository, when combined with dropout. Replacing this checkpointing implementation with recent Pytorch gradient checkpointing fixes the issue.
Minimal Reproduction notebook (Colab, CPU-only):
https://colab.research.google.com/drive/1dJByrYCSjGdXrleJIDpkuz_wFgLkaNbI?usp=sharing
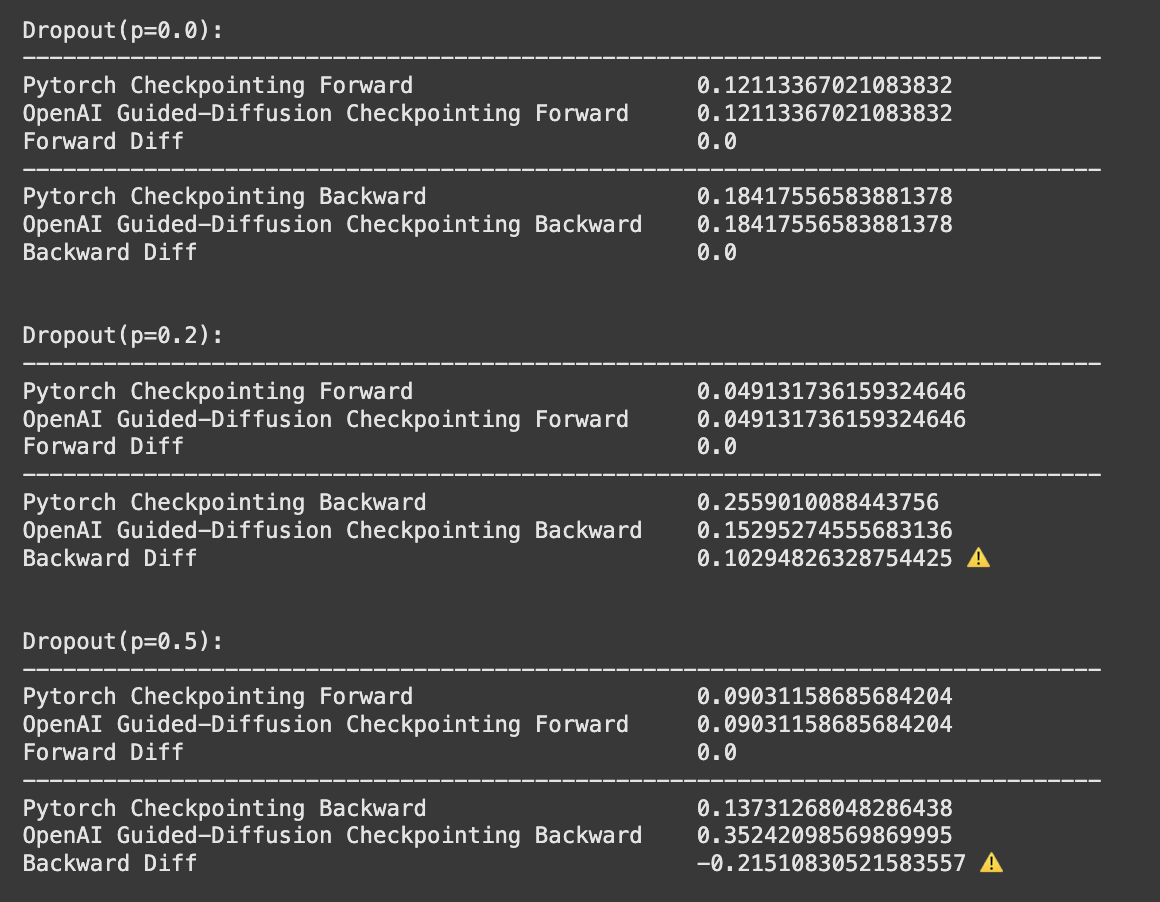
The error only is present with dropout p > 0.0, and it scales up in magnitude with the dropout probability.
Why didn’t we catch this earlier?
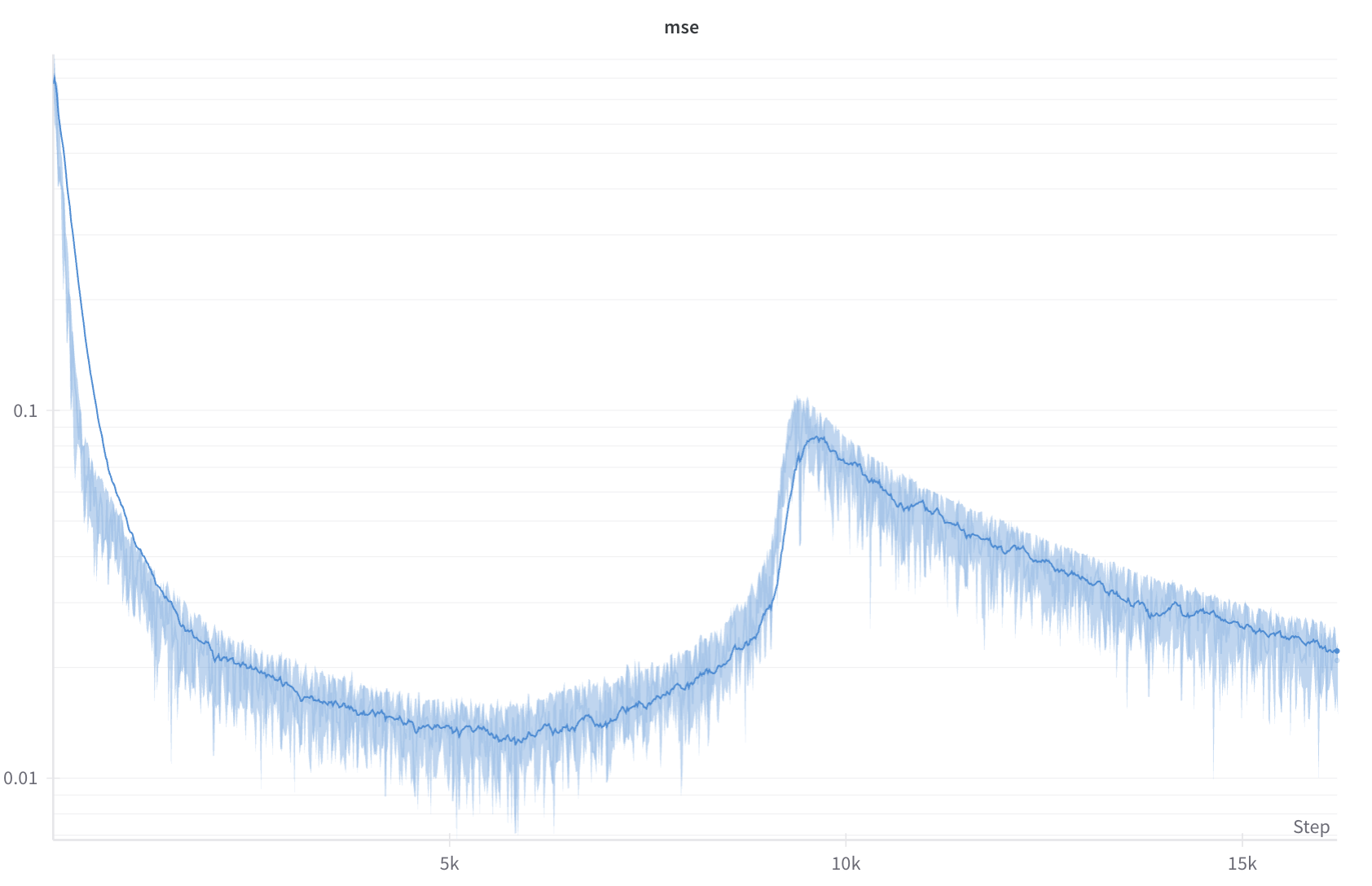
We ran the usual single-GPU tests. Model convergence looked health for the first 5k steps. Unfortunately the RNG-mismatch error compounds gradually: the bias per step is tiny, but after ~5 k updates (≈ 4h on one H100) the loss curve bends upward. Nothing in the early metrics signalled trouble.
This project was the first time I encountered a situation like this in a model training:
Model looks to be converging fine up until 5k steps in (around 1.5 epochs on our dataset), then starts slowly diverging. It peaks much later (around 2.5 epochs), then loss starts dropping again. But the model looks permanently damaged from the spike— it never recovers the same minimum again.
This is much unlike traditional loss spikes, which are usually much more sudden and can usually be attributed to large gradients or learning rates. On larger models, those can be hard to prevent, but modern optimizers have helped eliminate them. This loss spike is instead characterized by a slow gradual rise in loss early on during training. Gradient norms seemed perfectly typical, and no metric seemed to have any large spikes.
This error first showed up several hours into a cluster training for a model that was new, but very similar to our previous completed models. We learned that this error persisted on a single GPU.
Reproducibility was difficult.
Without knowing what the error was, any changes we made to speed up reproducibility only delayed the error proportionally. Reducing model size, dataset size, batch size, or simplifying the training process only increased the number of steps needed for the same error spike to happen. The fastest we were able to determine failure was just under 2 hours.
Experiments included
- Removing checkpointing
- Using the old model
- Minimizing the training loop
- Using synthetic data
- Removing RoPE
- Simplifying the optimizer
- Removing Cross-Attention (unconditional)
- Removing batch transformations
- Overfitting on 1 object
- Adding gradient clipping
- Adding QKNorm
Resolution When we finally pinpointed the error, it was clear in the loss.
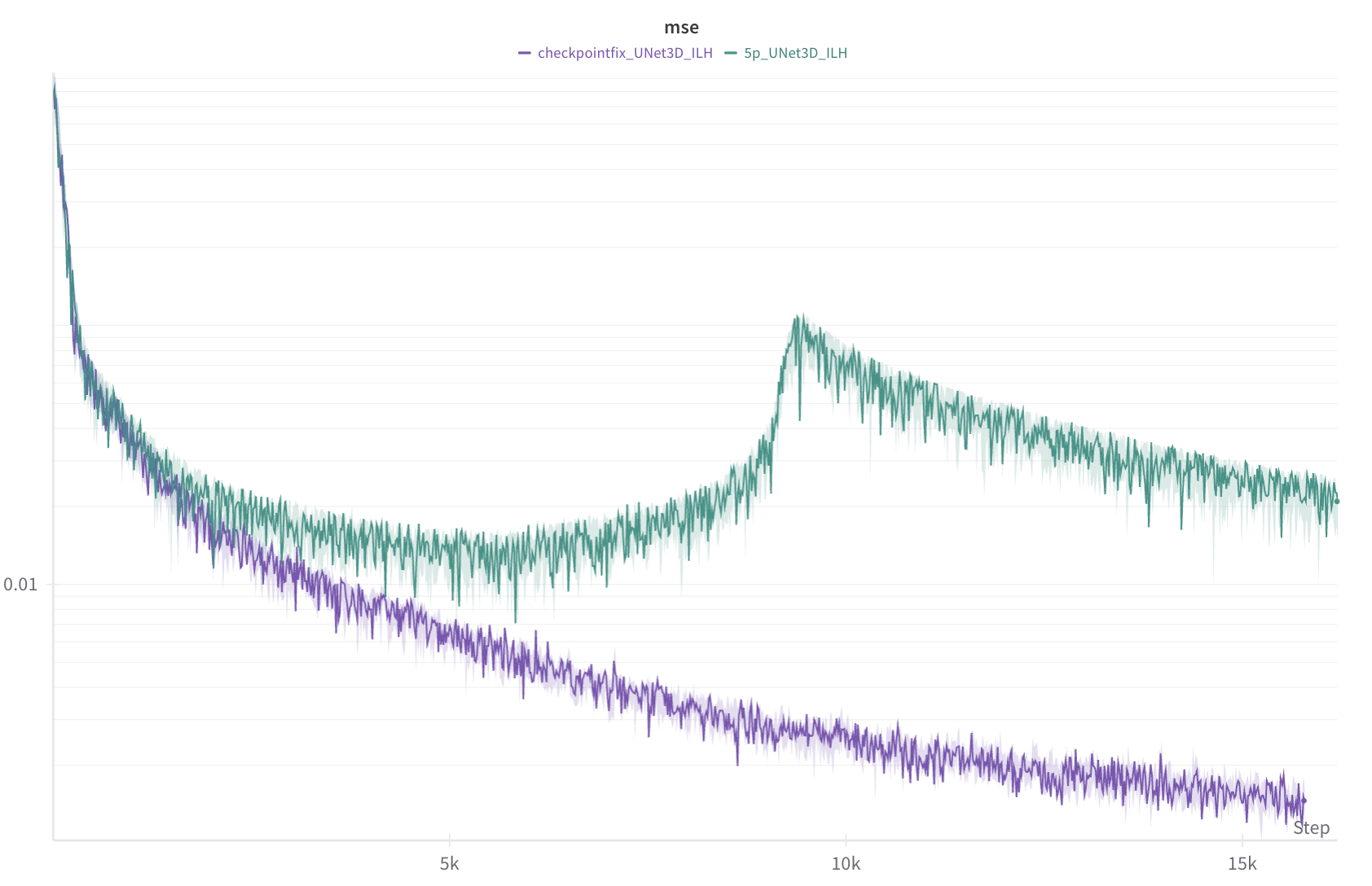
There was improvement in results even before the step where loss started to diverge previously. This demonstrates that the issue didn’t start to affect training midway through, but instead degraded results all along! We determined that an incorrect implementation of checkpointing caused the backward pass calculations to be incorrect when combined with dropout.
The custom checkpoint helper that ships with OpenAI’s guided-diffusion repo re-runs the forward pass during backprop without restoring the RNG state. Every stochastic layer inside the block, like dropout, therefore sees a different random mask the second time around, so the gradients you back-propagate no longer match the loss you just computed.
Switching from the custom helper to either variant of torch.utils.checkpoint (we use the newer use_reentrant=False) fixes the mismatch because PyTorch automatically restores RNG state between the recomputed forward and the original forward.
Checklist for you:
- Are you using any custom checkpoint helper?
- Does your forward contain stochastic modules?
- Did you freeze and restore RNG state inside custom_backward?
Takeaways:
- A gradual, early-epoch rise signals forward/backward mismatch, not typical exploding-grad spikes.
- The source of this divergence was very difficult to find. I would never have thought to check my checkpointing implementation when this bug first presented itself, and instead looked to make stabilizing additions. The main debugging lesson is that when you find yourself lost about what the issue could be, start by replacing components with bare-minimum versions.
- Example: To determine if it’s a data issue, use a synthetic dataset. Since our task required first using an encoder on the input data, we directly created synthetic latent data with patterns for our model to learn. This ruled out both the data and the encoder being the root cause.
- Attempts at fixing the root problem may have just made the problem harder to reproduce. Adding stronger gradient clipping, lowering learning rate, and similar tweaks only delayed the time the loss spike happened.
References:
- Chen et al., “Training Deep Nets with Sublinear Memory Cost,” ICML 2016 – original checkpointing.
- OpenAI Guided Diffusion Github. https://github.com/openai/guided-diffusion/
- PyTorch docs: torch.utils.checkpoint.